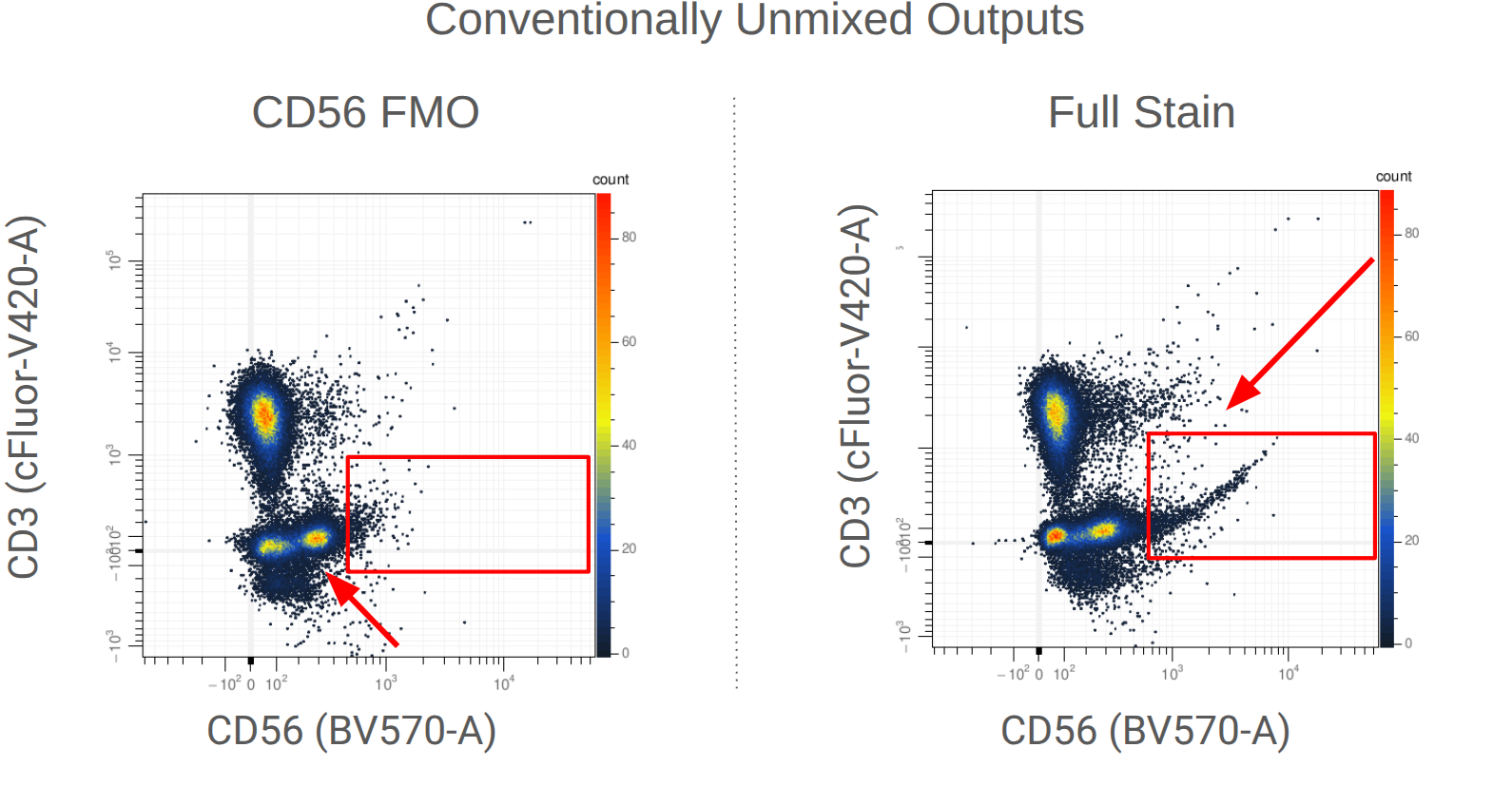
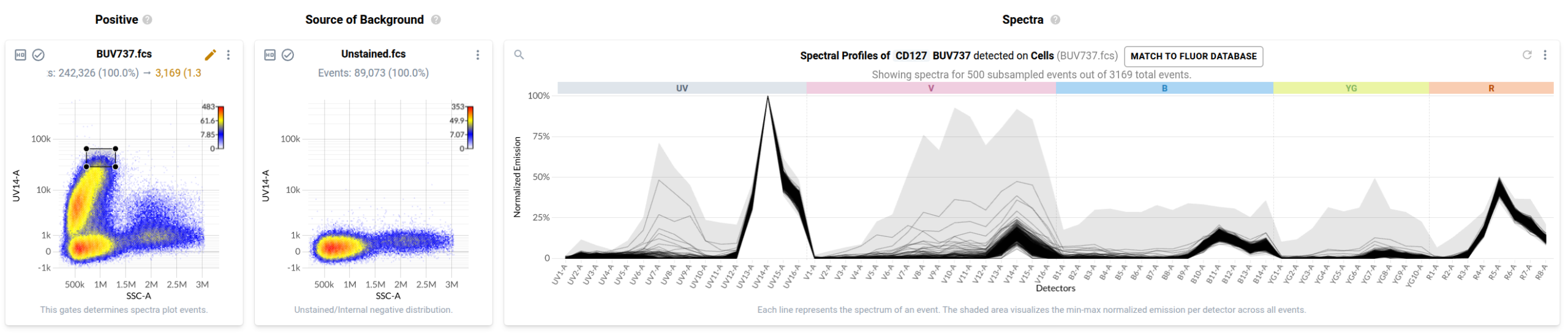
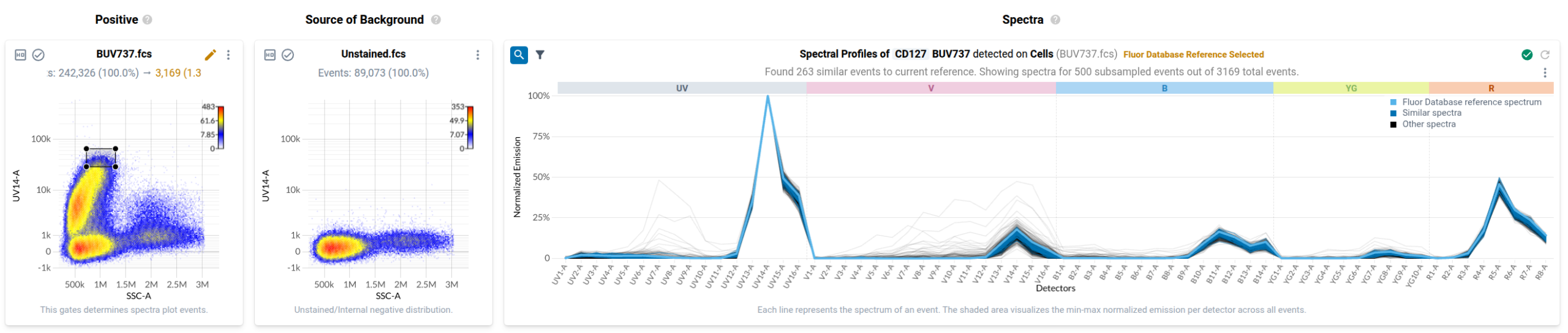
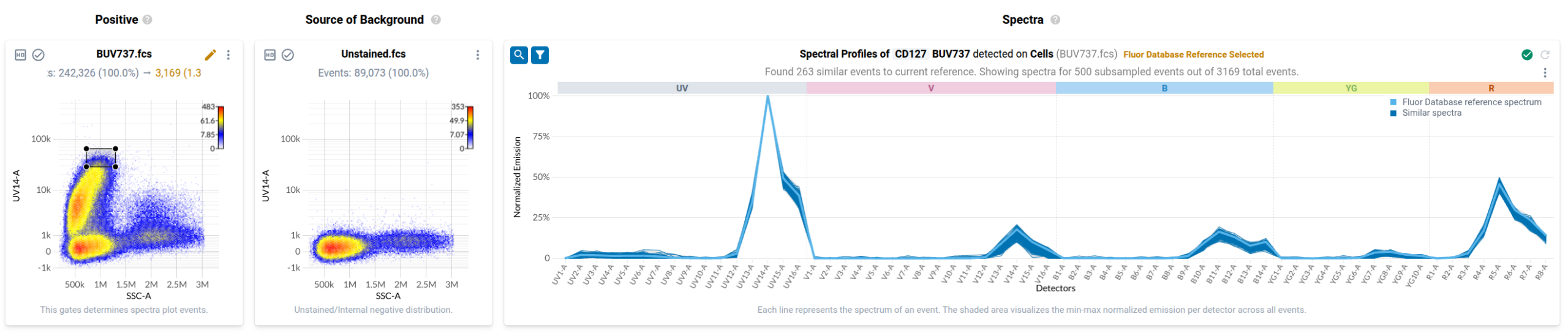
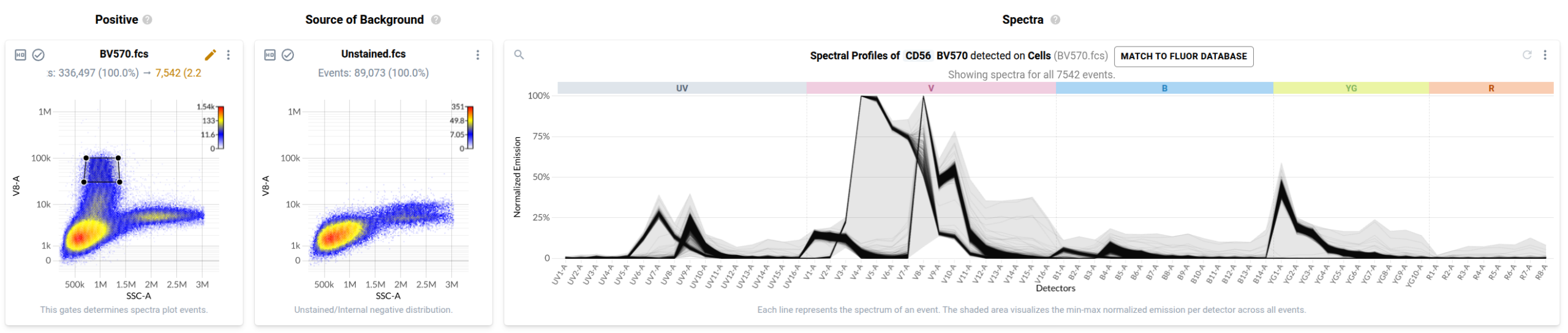
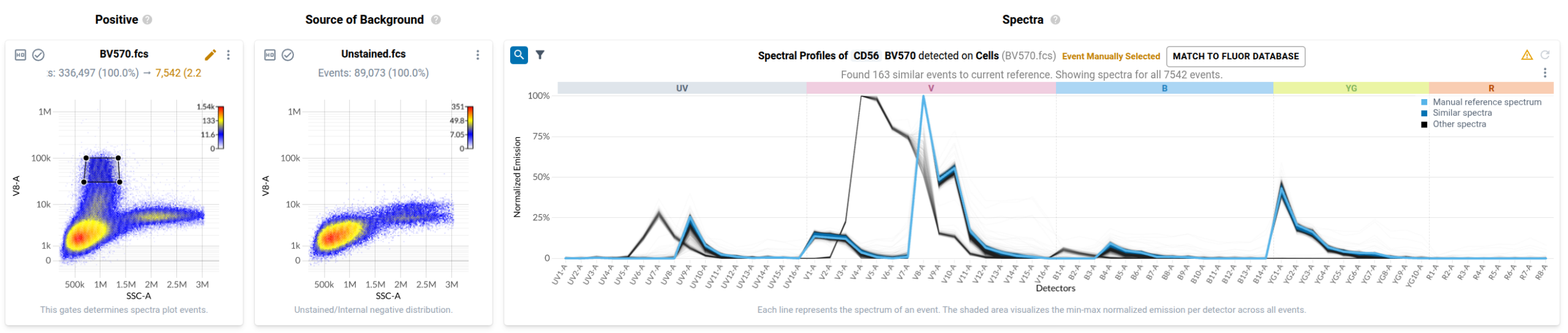
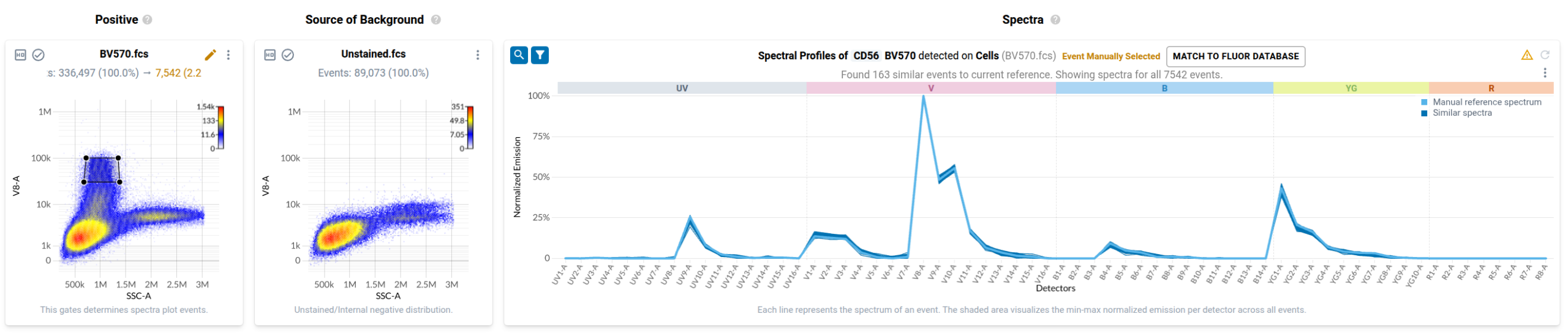
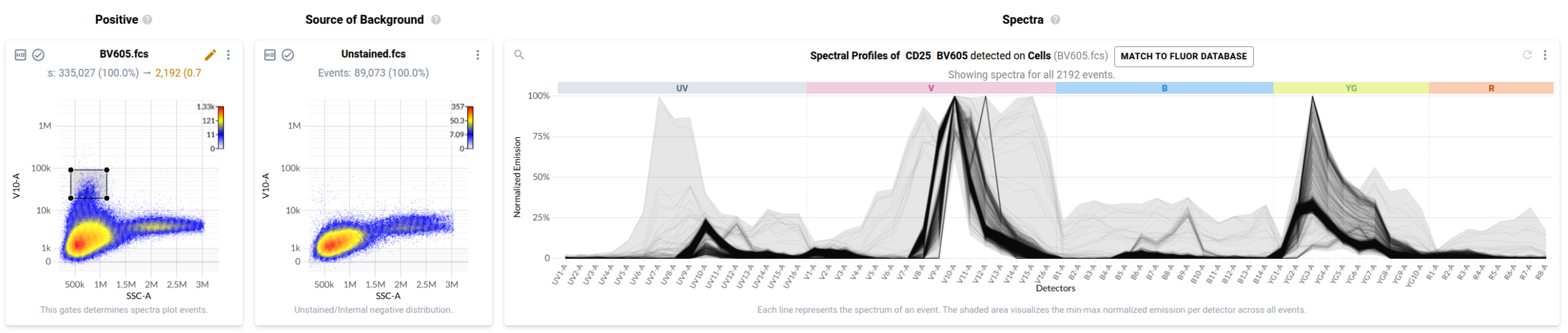
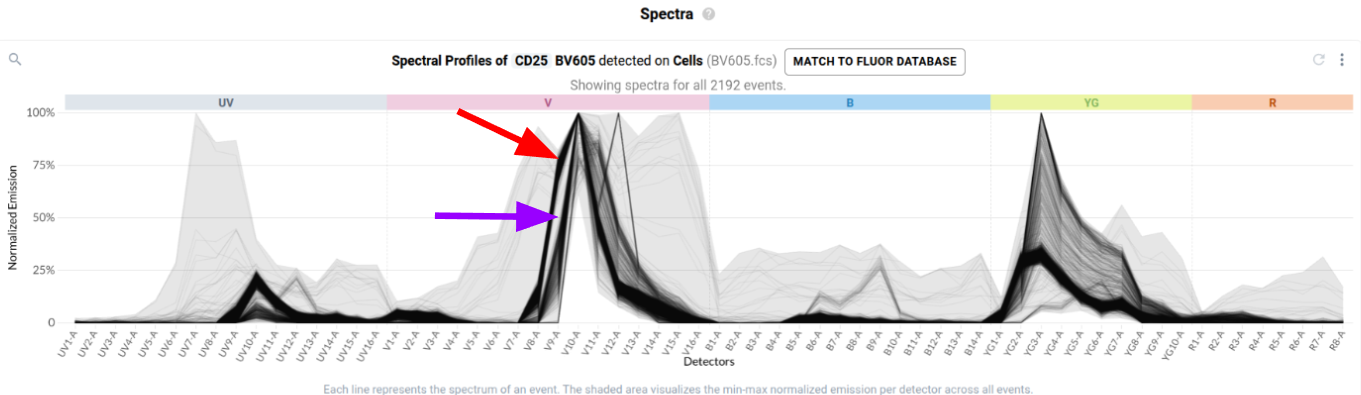
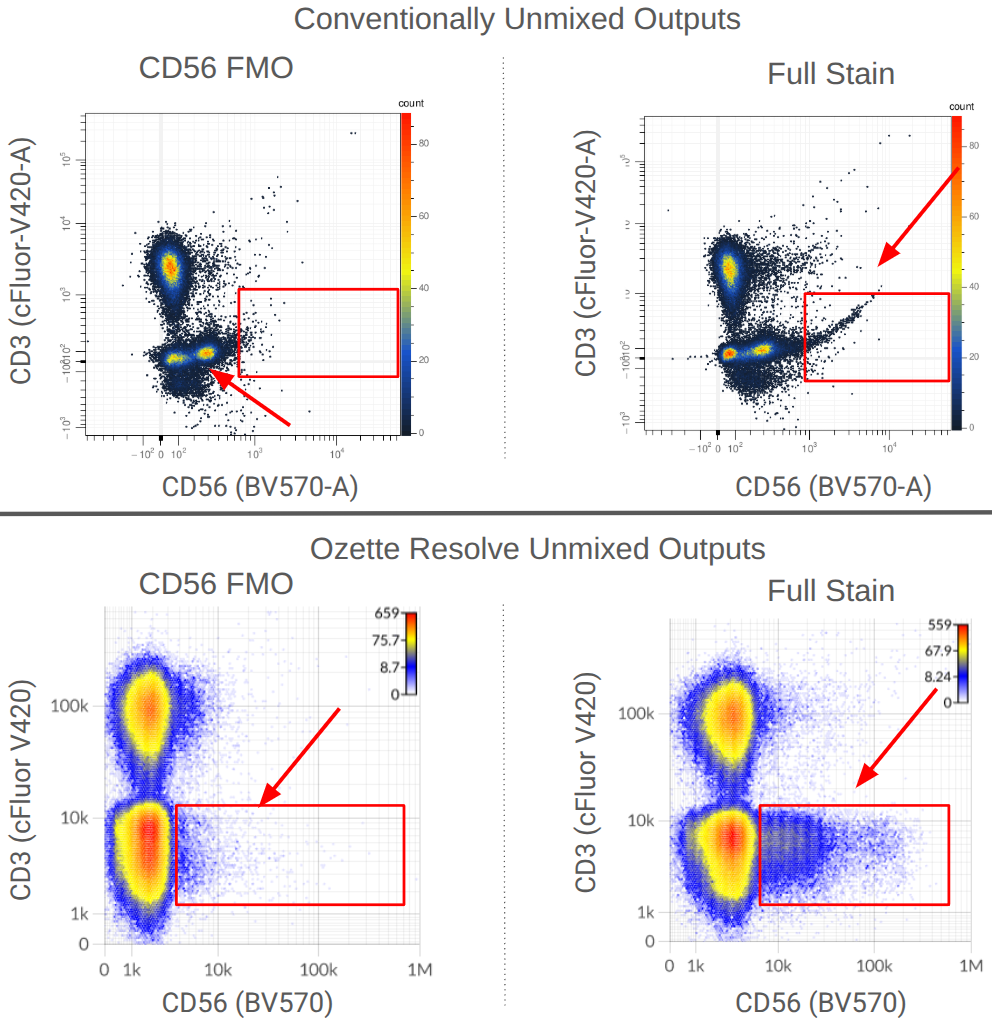
To many trained operators, this view is unremarkable: the fluorophore-conjugated antibody has labelled events in the file, and this plot is within expectation. Contrast this to the plot produced by a control for BV570 conjugated to anti-CD56 that has been contaminated by events stained with BV480 conjugated to anti-CD45RA.
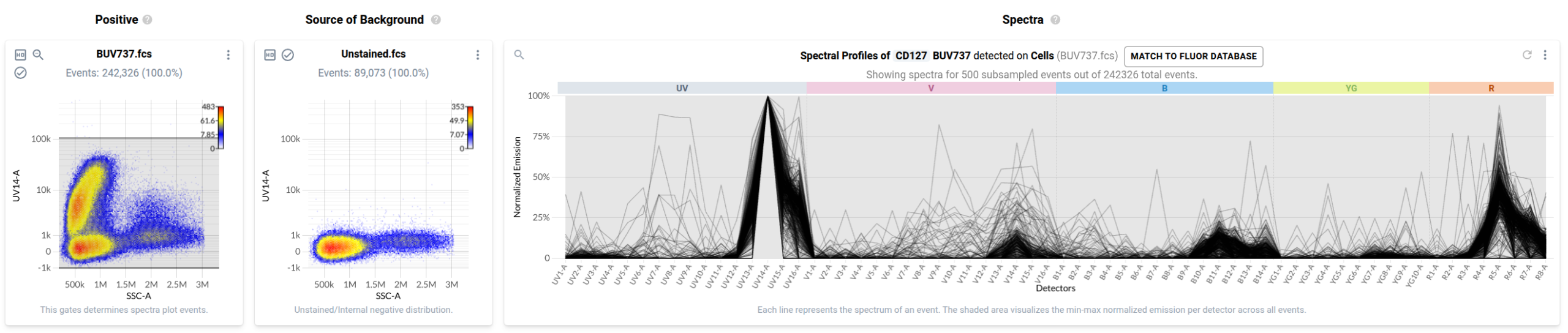
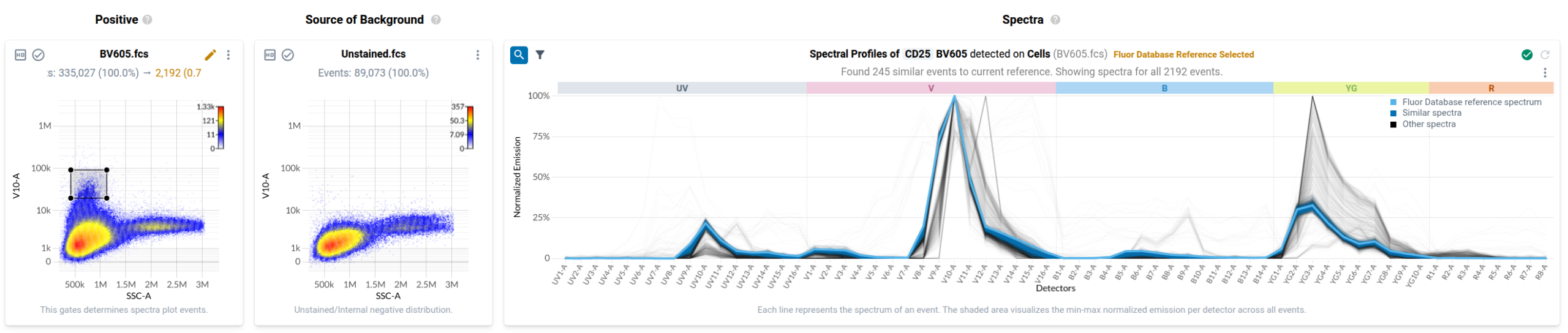
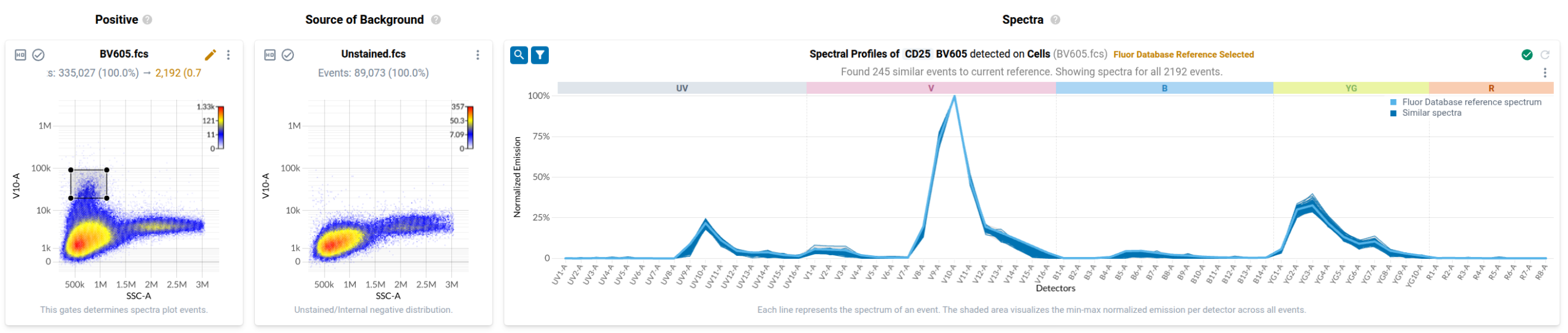
In the final step of the workflow, users identify events in each control that have been labelled with the fluorophore-conjugated antibody or fluorescent dye. Resolve provides several tools to help with this task. First, it provides event-level views of the spectra measured in your single stained controls in a purpose-built spectral plot. Here’s what the default view looks like for the anti-CD127 BUV737 control.